摘要:
如何预测新冠确诊病人数吗?AI算法模型师之四件评估“法器”!
导语
在AI领域,针对机器学习、自然语言处理等算法模型的评估(evaluation)是一项非常重要的工作,在海量数据中,为使算法模型趋向更准确,需要借助评估方法对算法模型进行评估,然后才能对模型进行针对性的优化、提升算法效率。
本文小编介绍四种评估方法,它们就像法师(数据科学家)使用的法器一样,有着对算法模型评判的奇妙法力,同时能产生算法模型的评估打分结果,为后续算法模型的优化提供依据。这四大法器分别是:准确率(Accuracy)、精确率(Precision)、召回率(Recall)和综合评价指标(F1-Measure)。要当好一个合格的算法师,我们需要熟练掌握这些法器,下面我们逐一摩挲一下它们。
古时射箭技艺高超的射手一般都被称为“神射手”,“神射手”射出的箭能够“百步穿杨”、中靶率基本是百发百中,这个就是准确率的概念。而在机器学习中,对于算法模型预测的准确率,也是看其能够百发几中的概率。本文介绍的第一个评估法器就是:Accuracy,即准确率评估,它是对模型预测的正确数量所占总预测数量的比例进行评估的一项指标。
新冠疫情爆发期,对病患的核算检测进行确诊是一项重要工作,我们可以用大数据AI算法进行新冠肺炎感染病患的进行预测。在预测中,可以使用准确率公式来表达新冠肺炎预测是否感染的正确及错误:
其中:TP=预测新冠确诊病人数,并判断正确;TN=预测健康人数,并判断正确;FP=预测新冠确诊病人数,但判断错误;FN=预测健康人数,但判断错误。
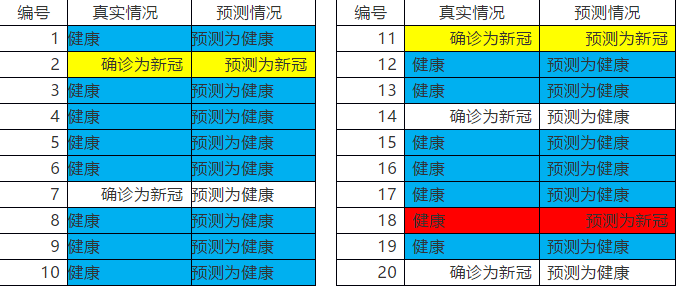
我们可以举例,假设对20人进行新冠肺炎的确诊情况进行预测,该数据实际情况和使用二元分类算法模型(即判断要么确诊新冠、要么为健康)预测如下:
以上,黄色——TP=2,预测与实际都为新冠感染患者人数(预测正确)
蓝色——TN=14,预测与实际都为健康人数(预测正确)
红色——FP=1,预测为新冠感染患者,实际是健康的人数(预测错误)
白色——FN=3,预测为健康人员,实际是新冠感染患者人数(预测错误)
从该计算结果来看,预测的结果表现是还算可以的,分类准确率达到80%。那么是不是我们选用的算法模型就是比较出色的模型呢?
我们可以仔细分析一下数据情况,深入理解一下模型预测的效果:
20人中,15人健康,剩余5人感染了新冠肺炎,模型预测健康的人数14人,比率高达93.3%,效果不错;但是感染了新冠的实际总人数为5,错误的预测其中3人为健康,比率达到了3/5=60%,说明从这个角度预测准确率才有40%,错误率较高,模型实际上是达不到预测的精确要求的。
这样,对模型的评估只使用这个准确率评估法器肯定是还不够的,算法师还需要祭出后面要说的新法器——精确率、召回率评估法器。
2评估法器二:诸葛神机弩——精确率评估
对于上述进行新冠肺炎患者预测的数据集,其分类是不太平衡的,即确诊人员和健康人员的分布比较不均衡,数量差异较大。算法师如果只使用一项准确率法器来判断模型是否有效并不合理。
在三国战争中,为了成批地精确打击敌人,诸葛亮发明了诸葛神机弩,其命中率高、打击面大,是让敌人闻风丧胆的战争利器,使用精确率(Precision)法器来评估模型,也可以比喻为算法师的诸葛神机弩。
其中:TP=预测新冠确诊病人数,并判断正确;FP=预测的新冠确诊病人数,但判断错误。
我们还是采用前面的数据集来对精确率进行评估,计算如下:
即模型在对上述数据集预测出新冠肺炎感染者的精确率是66.67%。
算法师除了以上描述的法器,还可以使用一个妙技:回头望月斩——进行召回率评估。回头望月斩通常会在武功对决里出现,一般指一个招式用老的瞬间,在敌人背后出其不意地回头使出一招,打击敌人。在这里,我们可以形容分类算法模型对所有错误和正确的预测中预测正确的比例(也可以理解为对模型错误预测的回顾和评估),通俗也可以称为“查全率”。
其中:TP=预测新冠确诊病人数,并判断正确;FN=预测为健康、但实际为新冠感染者人数。
我们还是采用前面的数据集来对召回率进行评估,计算如下:
即对上述数据集,模型能正确预测出所有新冠肺炎感染者的比率只有40%。
因此,算法师要达到全面评估模型的有效性,必须同时检查精确率和召回率,但是两者的提升是有矛盾的,提高模型的精确率就会降低其召回率,反之亦然。因此算法师还需要利用一个更高端的评估法器来进行综合评估——F1综合评估法。
国家在调控宏观经济时,经常采用一系列调控组合拳。武功高手通常打出一套让人应接不暇的组合拳,虚中有实、实中有虚,会让对手无法接招并取胜。算法师在评估模型时,也可以采用类似的评估组合,本文推荐一个常用的综合评估法器:F1综合评估法(F1-Measure),又称F1-Score,是精确率(实招)和召回率(虚招)的加权调和平均,算是模型评估的一套精准组合拳,也可以比喻为一个组合了前两种评估法器的大法器。
其中,P为精确率(Precision), R为召回率(Recall)。
(注:F1综合评估是统计学中F-Measure在权重参数=1时的一个特例,即精确率与召回率权重一致,本文限于篇幅,只对评估常用的F1评估进行描述。)
继续利用上述的数据集,根据前面计算出的精确率和召回率,便可得出其F1值如下:
结果是0.5,在模型评估中,当这个值较高时,说明算法模型的效果比较理想,目前看来这个分值反映出模型效果比较一般。
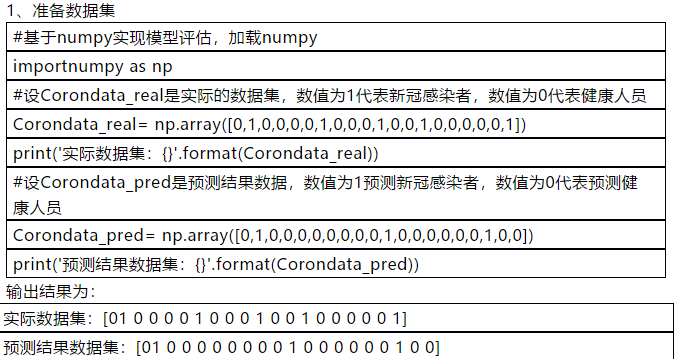
为了让读者更好地理解四件法器的功效,我们仍然使用上述的预测新冠感染者的数据集,通过python实战演练一下。
#设Corondata_real是实际的数据集,数值为1代表新冠感染者,数值为0代表健康人员
Corondata_real= np.array([0,1,0,0,0,0,1,0,0,0,1,0,0,1,0,0,0,0,0,1])
print('实际数据集:{}'.format(Corondata_real))
#设Corondata_pred是预测结果数据,数值为1预测新冠感染者,数值为0代表预测健康人员
Corondata_pred= np.array([0,1,0,0,0,0,0,0,0,0,1,0,0,0,0,0,0,1,0,0])
print('预测结果数据集:{}'.format(Corondata_pred))
实际数据集:[01 0 0 0 0 1 0 0 0 1 0 0 1 0 0 0 0 0 1]
预测结果数据集:[01 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 1 0 0]
#预测与实际都为新冠感染患者人数(预测正确),truepositive
TP=np.sum(np.logical_and(np.equal(Corondata_real,1),np.equal(Corondata_pred,1)))
print('预测与实际都为新冠感染患者人数(预测正确):{}'.format(TP))
#预测与实际都为健康人数(预测正确),falsepositive
FP=np.sum(np.logical_and(np.equal(Corondata_real,0),np.equal(Corondata_pred,1)))
print('预测与实际都为健康人数(预测正确):{}'.format(FP))
#预测为新冠感染患者,实际是健康的人数(预测错误),truenegative
TN=np.sum(np.logical_and(np.equal(Corondata_real,1),np.equal(Corondata_pred,0)))
print('预测为新冠感染患者,实际是健康的人数(预测错误):{}'.format(TN))
#预测为健康人员,实际是新冠感染患者人数(预测错误),falsenegative
FN=np.sum(np.logical_and(np.equal(Corondata_real,0),np.equal(Corondata_pred,0)))
print('预测为健康人员,实际是新冠感染患者人数(预测错误):{}'.format(FN))
预测为新冠感染患者,实际是健康的人数(预测错误):3
预测为健康人员,实际是新冠感染患者人数(预测错误):14
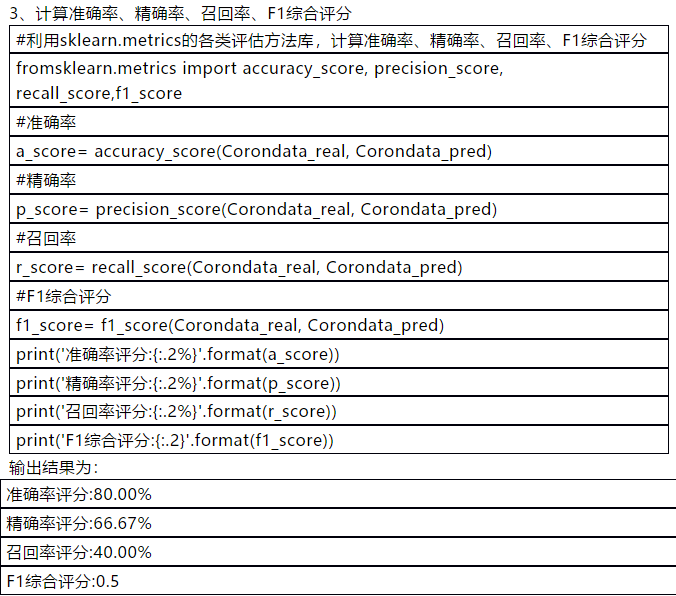
#利用sklearn.metrics的各类评估方法库,计算准确率、精确率、召回率、F1综合评分
fromsklearn.metrics import accuracy_score, precision_score, recall_score,f1_score
a_score= accuracy_score(Corondata_real, Corondata_pred)
p_score= precision_score(Corondata_real, Corondata_pred)
r_score= recall_score(Corondata_real, Corondata_pred)
f1_score= f1_score(Corondata_real, Corondata_pred)
print('准确率评分:{:.2%}'.format(a_score))
print('精确率评分:{:.2%}'.format(p_score))
print('召回率评分:{:.2%}'.format(r_score))
print('F1综合评分:{:.2}'.format(f1_score))
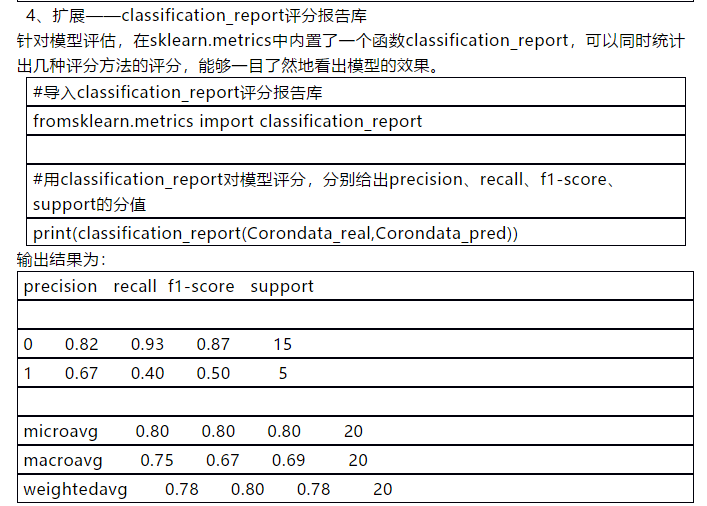
4、扩展——classification_report评分报告库
针对模型评估,在sklearn.metrics中内置了一个函数classification_report,可以同时统计出几种评分方法的评分,能够一目了然地看出模型的效果。
#导入classification_report评分报告库
fromsklearn.metrics import classification_report
#用classification_report对模型评分,分别给出precision、recall、f1-score、support的分值
print(classification_report(Corondata_real,Corondata_pred))
precision recall f1-score support
microavg 0.80 0.80 0.80 20
macroavg 0.75 0.67 0.69 20
weightedavg 0.78 0.80 0.78 20
上述结果对精度(Precision)、召回率(Recall)、f1分数(f1-score)、support四项指标的分值以列表形式概览展示。这也对模型评估起到了很大的帮助。
根据以上对四件评估法器的实战演练,我们可以小结如下:
对于模型评估,本文推荐的四件评估法器都能够对模型打出分值,但各有千秋,均能体现出模型的一定效果。在实战中,算法模型师可以采用这四件法器多方面进行评估,以方便后续对模型进行优化。
本文介绍的是较为普遍常用的评估方法,对模型进行评分还可以有很多其它的方法,例如交叉验证法、ROC(Receiver Operating Characteristic Curve)、AUC(Area Under Curve)、R2分数等,限于篇幅,我们在这里不再展开,读者可以在网上搜索查看。
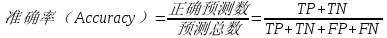
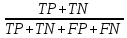
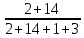
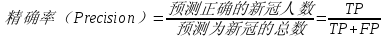
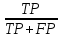
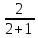
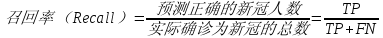
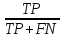
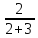
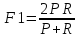
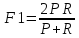
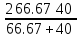


















 京公网安备 11010802020714号
京公网安备 11010802020714号