摘要:
【python培训】一文教你如何轻松实战Python时间序列数据挖掘!
前言
随着云计算和物联网(IoT)的急速发展,我们无时无刻都被时间序列数据包围着。从经济管理再到工程领域,时间序列数据挖掘有着广泛应用。例如证券市场中股票的交易价格与交易量、外汇市场上的汇率、期货和黄金的交易价格以及各种类型的指数等,这些数据都形成一个持续不断的时间序列。利用时间序列数据挖掘,可以获得数据中蕴含的与时间相关的有用信息,实现知识的提取。时间序列数据挖掘是大数据挖掘研究领域里的一个重要方向之一。
众所周知,时间序列数据本身所具备的高维性、复杂性、动态性、高噪声特性以及容易达到大规模的特性。因此如何轻松进行时间序列数据挖掘是具有大挑战性。本文将介绍时间序列数据挖掘开源库——MatrixProfile,并在Python的环境下使用高效简洁的程序来完成复杂的时间序列数据挖掘。 MatrixProfile的基本原理很简单。可以先试想一个问题,如果从时间序列数据中提取一个片段并沿着时间序列的其余部分滑动,那么它在每个新位置与时间序列片段的重叠相似的程度是什么样子的?更具体地说,我们可以计算子序列与同一长度的每个时间序列片段之间的欧几里德距离,从而建立所谓的时间序列片段的距离模式(distanceprofile)。
如果子序列在数据中重复自身,则将至少有一个完全匹配,并且最小欧氏距离将为零(或在存在噪声的情况下接近于零)。如图所示,如果提取的子序列为重复模式(RepeatedPatterns)片段,那么重复模式片段沿着整个时间序列滑动时,与自身重复片段的最小欧式距离为零(红色部分)。从红色曲线可以看出,相比之下,如果子序列是高度唯一的(比如它包含一个显著的异常值),那么匹配将很差(蓝色曲线中的anomaly)。然后,在时间序列中滑动每个可能的片段,建立一个距离模式的集合。
MatrixProfile主要是进行识别异常事件(或不协调“discords”)和重复模式(或模体“motifs”)。这是两项基本的时间序列任务。其中MatrixProfile分为两个重要组成部分:距离模式(distanceprofile)和模式索引(profileindex)。距离模式是归一化最小欧氏距离向量。模式索引包含其第一近邻索引。换句话说,它是其最相似子序列的位置。
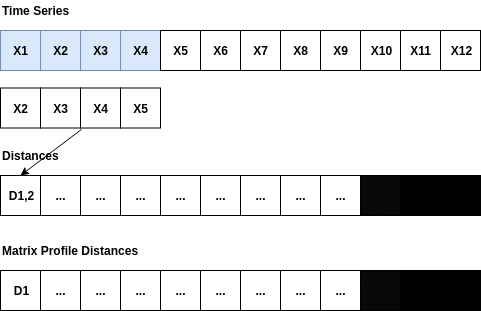
MatrixProfile主要采用了用滑动窗口的算法来计算,如下图所示。图中的滑动窗口X2到X5在时间序列(X1,…,X12)上滑动,分别计算滑动窗口与每个子序列的点积。当计算完所有的点积(D1,2,…,D9,2)后,应用排除区域(exclusionzone)进行处理。并将最小距离存储在MatrixProfile的距离模式中,丢弃其余的距离。其中,由于子序列是从时间序列本身提取的,因此需要设置图中排除区域来防止无价值匹配。比如,子序列片段(X1,X2,X3,X4)与滑动窗口(X2,X3,X4,X5)相似度非常高,被视为无价值匹配或平凡匹配。
MatrixProfile API(MPA)应用接口库
MatrixProfile库支持三种最常用的数据科学语言Python、R和Golang。它提供易于使用的接口函数MatrixProfileAPI(MPA),这是一个用R、Python和Golang编写的通用代码库。不管是对时间序列分析毫无经验的新手还是专家都很有帮助。而且它已经被广泛地使用,包括如何挖掘网站用户数据、订单量和其他关键业务应用之间的关系。下面使用Python来进行实战训练。
这三个核心功能作为底层嵌套在具有用户可视化的界面Analyze的模块里面,可以使那些对MatrixProfile内部工作原理一无所知的人能够快速地利用它来处理自己的时间序列数据。
首先需要配置MatrixProfile的安装环境,建议使用Anaconda。Anaconda是一个用于科学计算的Python发行版,内置很多用于学计算工具Python第三方库,非常方便使用。然后,在AnacondaPrompt终端使用下面语句来安装MatrixProfile库。
安装完后,我们将使用MatrixProfile API(MPA)应用接口库来分析如下所示的合成时间序列。
import matrixprofile as mp
from matplotlib import pyplot as plt
dataset =mp.datasets.load('motifs-discords-small')
profile = mp.compute(dataset['data'],window_size)
profile = mp.discover.discords(profile)
mp_adjusted = np.append(profile['mp'],np.zeros(profile['w'] - 1) + np.nan)
plt.plot(np.arange(len(profile['data']['ts'])),profile['data']['ts'])
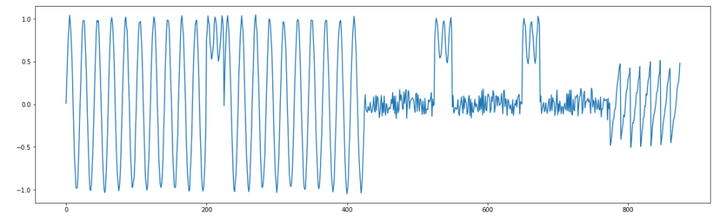
从合成的时间序列数据图中可以发现,明显存在模式不协调现象。图中前面是规律震荡变化的正弦曲线模式,而后面是两种不同的模式。然而,一个直接的问题是,该如何选择子序列长度。图中横坐标0-500范围内是否只有两个正弦模体?我们可以使用应用接口库MPA中的analyze函数来自动处理这个问题,完整程序代码如下。
import matrixprofile as mp
from matplotlib import pyplot as plt
dataset =mp.datasets.load('motifs-discords-small')
profile = mp.compute(dataset['data'],window_size)
profile = mp.discover.discords(profile)
profile, figures =mp.analyze(profile['data']['ts'])
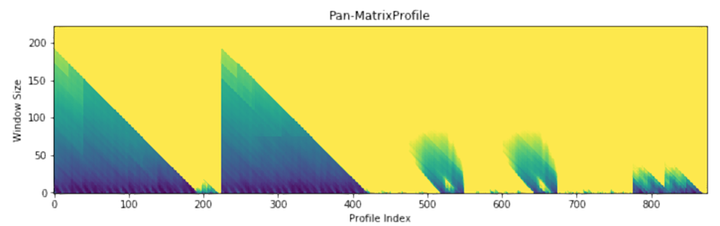
由于没有指定任何关于子序列长度的信息,“analyze”首先利用称为panmatrix profile(简称PMP)的强大计算来生成有助于评估不同子序列长度的模式图,如下所示。
简而言之,它是对所有可能的子序列长度的全局计算,并压缩为一个可视化模式图。X轴是矩阵模式的索引,Y轴是相应的子序列长度。图中颜色越暗,代表欧几里德距离就越低。
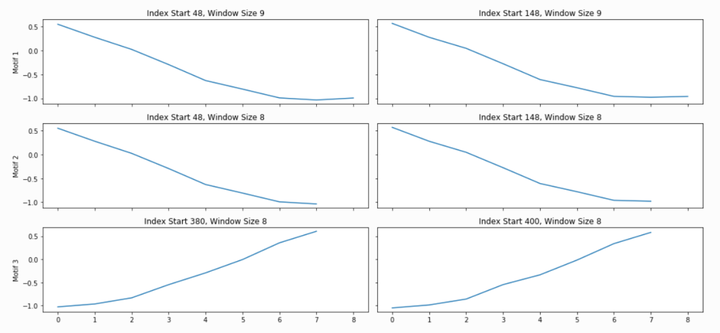
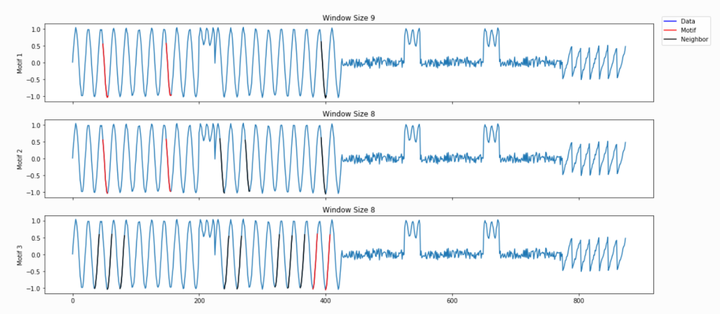
这里,analyze函数将结合PMP和一个隐藏的算法,从所有可能的滑动窗口大小中选择合理的模体和不协调。由“analyze”创建的附加图形显示前三个模体和前三个不协调,以及相应的窗口大小和在矩阵模式中的索引位置(以及扩展的时间序列)。
下图中蓝色部分代表合成时间序列数据,红色部分代表模体,黑色部分是相似近邻。
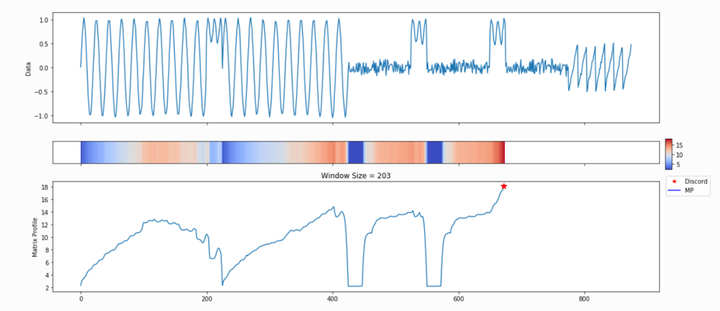
这里采用的是程序默认的参数,运行后会自动得到很多结果。我们也可以更改滑动窗口的大小。程序会自动找出不协调的点,如下图所示。
profile,figures = mp.analyze(profile['data']['ts'],windows=203)
滑动窗口大小为203时,出现不协调的点(红色五角星)
比起常规的时间序列挖掘算法,MatrixProfileAPI(MPA)应用接口库提供了一个较为简洁的方式,能让你更轻松地分析和挖掘时间序列数据,当然,上面只是采用了MPA内置函数默认的参数来进行说明。如果想进一步了解MPA的用法,并将其应用到自己特定的应用场景中,可以在网上查找MPA官方使用手册。
以上,就是小编为大家整理的《教你如何轻松实战Python时间序列数据挖掘!》,希望能够对大家有所帮助!




 手机端官网
手机端官网

 京公网安备 11010802020714号
京公网安备 11010802020714号