摘要:
【python】四个行为特征来判断是否需要对该人进行核酸检测!
“To be,ornot to be:thatis thequestion”(生存还是毁灭:这是一个问题),这是著名的莎士比亚悲剧《哈姆雷特》中的主人公一句非常经典的独白,也是数百年来经常困扰人们的选择问题。这段哈姆雷特式问题的台词,经常用来形容一个人在犹豫在思考时候的两难情况,用现代人的说法就是“选择困难症”。人们经常纠结于各种选择,生怕选错了,就会陷入“蓝瘦香菇”的困境。
人们在面临选择难题的时候经常想:如果能未卜先知,那该多好。实际上,在人工智能领域,就有一种预测算法,利用树杈的形状,非常形象地来解决这种选择问题,这就是决策树算法,它是一个非常广泛应用的算法,其原理是通过对一系列问题进行“是/否”的推导,最终实现决策。在机器学习发展到如今,决策树算法越来越得到更多的应用,我们也可以说它是解决“选择困难症”的良药。本文为了让读者朋友较好理解该算法,用python编程进行一个实际应用的示范。
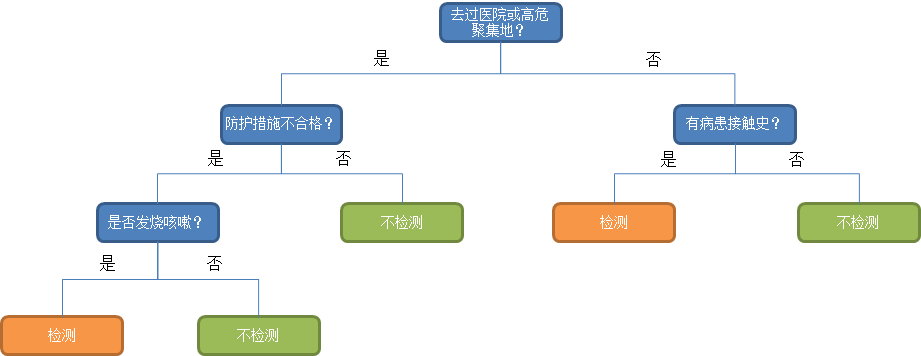
决策树算法是一种典型的、逼近离散函数值的分类方法。主要是先对数据进行处理,利用归纳算法生成可读的规则和决策树,然后使用决策对新数据进行分析。决策树算法应用非常广泛,例如在目前新冠疫情下,由于核酸检测条件和资源有限,不能够对所有人都进行检测,因此对有疑似感染人员的一些行为特征进行推导,最终判断其是否需要进行核酸检测来进一步确诊,也是很有必要的。比如调查和征询病人的近期行为:“去过医院或高危聚集地、防护措施是否到位、有病患接触史、是否发烧咳嗽”,这四个行为特征来判断是否需要对该人进行核酸检测,从而进一步确诊。
图中最末端的5个节点,就是选择后的判定结果,也称为决策树的树叶。如果样本的特征特别多、数据量大,就需要使用机器学习的办法来建立决策树的模型进行预测了。其中,决策树算法的最大深度,也就是其max_depth参数,代表了决策树的复杂程度,即上述例子中做出问题判断的数量,问题判断数量越多,就代表决策树的深度越深,这个模型的计算也越复杂。
在上面的例子中,决策树很形象地把新冠疑似人员的几类行为做了推导,如果一个疑似人员虽然“没有去过医院或高危聚集地、但是有病患接触史”,就要考虑做核酸检测;如果一个疑似人员“去过医院或高危聚集地、防护措施不到位、并且发烧咳嗽”,说明该病人感染可能性较大,就需要做核酸检测。通过决策树算法,对疑似人员进行选择核酸检测或不检测的判定进行预测,解决了核算检测的选择问题。
(注:以上例子仅为了解释决策树算法的模拟描述,不一定代表真实情况)
随着新冠疫情逐步得到缓解,长期宅在家中的人们都开始考虑去户外游玩,可是天气越来越热、或者下雨、大风等,能不能带家人一起出去游山玩水还得看老天爷的脸色。小明家有一个刚满四岁的小孩,疫情期间,“小神兽”在家里都快憋疯了,天天在家里是上蹿下跳的。马上就是周末了,小明看着家里被折腾的一片狼藉,他必须要做出周末是否能出行游玩的决策。同时他正好是一个大数据工程师,当然可以借助人工智能算法来预测天气以及出行的可能性,从而做出一个全家出行游玩的计划。本文就通过决策树算法,利用积累了一定时间的历史天气数据,模拟一下小明的预测,看看这个周末他能不能带全家一起出行游玩。
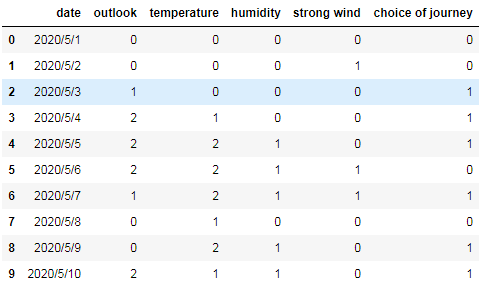
我们采用的数据集包含如下特征字段(为简略过程,将数据集的各自段值全部转换为数字):
日期-date、天气-outlook(0-晴天、1-阴天、2-雨天)、气温-temperature(0-炎热、1-适中、2-寒冷)、湿度-humidity(0-高、1-中、2-低)、大风-strongwind(0-有、1-无),另外还有一个输出分类结果:出行的选择-choiceof journey(1-是、0-否)。
data= pd.read_csv('weather.csv')
#把去掉预测目标Choiceof journey后的数据集作为训练数据集X
data.drop(['date'],axis = 1, inplace = True)
X= data.drop(['choice of journey'], axis = 1)
y= data['choice of journey'].values
生成训练集和测试集、使用决策树算法建模并评估模型分数。
fromsklearn.model_selection import train_test_split
X_train,X_test, y_train, y_test = train_test_split(X, y, random_state=42)
DT_clf= tree.DecisionTreeClassifier(max_depth=5)
DT_clf.fit(X_train,y_train)
print('决策树模型得分:{:.2f}'.format(DT_clf.score(X_test,y_test)))
可以看到,基于这个天气数据集训练的模型得到了0.85的评分,也就是说这个模型的预测准确率在85%,可以说预测准确率还不错,应该能够为小明解决出行的选择问题了。
在这个过程中,决策树在每一层当中都做了哪些事情呢?我们可以在Jupyternotebook中用一个名叫graphviz的库(首先需要借助Anaconda安装这个库),它能将决策树的工作流程展示出来。输入代码:
fromsklearn.tree import export_graphviz
export_graphviz(DT_clf,out_file=" weather.dot", class_names="choice ofjourney",feature_names=["outlook","temperature","humidity","strongwind"], impurity=False, filled=True)
withopen("weather.dot") as f:
graphviz.Source(dot_graph)
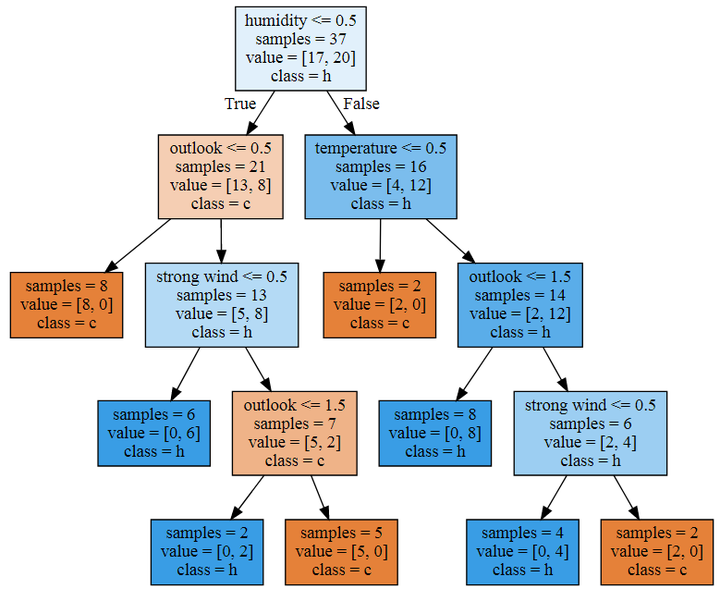
上图非常清晰地展现了决策树是如何进行预测的,可以看出,决策树模型首先对湿度进行判断,在湿度小于或等于0.5这个条件为True的情况下,决策树判断分类为c,如果是False,则判断为h,到下一层则对天气和温度进行判断,进一步对样本进行分类,以此类推,直到将样本全部放进2个分类当中。
模型建立好了,小明可以开始筹备周末的出行大计了,刚刚天气预告广播报道:本周末天气为——多云、气温26度(适中)、湿度65%(稍高)、风力3级(无大风)。
按之前对特征字段设定的对应关系,各特征值解释为数字是:[1,1,0,1]
我们可以利用上面步骤建立的决策树模型来预测一下,看看小明周末能不能带全家出去游玩。
pre= DT_clf.predict(weekend)
print("预测结果:[周末天气不错,可以去游玩!]")
print("预测结果:[很遗憾,周末天气不好,别去了]")
小明得到以上预测结果也很兴奋,马上开始准备出行计划、路线和设备。周末小明全家人高高兴兴地踏了一次青,大家反映都很不错,小明的父亲形象顿时伟岸起来。决策树算法解决了小明出行的“选择困难症”,小明也算利用他掌握的算法知识为家里做了一次贡献。
决策树算法(DecisionTree)在机器学习算法中,算是一个非常基础的算法,使用和预测也比较简单。以上的例子是一个理想状况的阐述,在机器学习的实际项目中,决策树算法经常会出现过拟合的问题,这会让模型的泛化性能大打折扣。为了避免过拟合的问题出现,在决策书算法的基础之上,科学家们又衍生出随机森林(RandomForests)和梯度上升决策树(GradientBoosted DecisionTrees,简称GBDT)算法,大大优化了决策树算法。限于篇幅,本文对这两个算法就不再深入介绍了,有兴趣的读者朋友可以自行学习和编程操作。



 手机端官网
手机端官网

 京公网安备 11010802020714号
京公网安备 11010802020714号