来源:北大青鸟总部 2023年02月17日 13:35
K最近邻(k-NearestNeighbor,K-NN)算法是一个有监督的机器学习算法,也被称为K-NN算法,由Cover和Hart于1968年提出。可以用于解决分类问题和回归问题。此外,作为一个理论上比较成熟的机器学习算法,关于K近邻算法的介绍有很多,比如算法执行的步骤、应用领域等。不过网上关于K近邻算法的大多数介绍都非常繁杂且缺乏简单实用的代码示例。这样不免会增加学习负担,在这篇文章中我们将针对这个问题以最简单的实例,带大家来轻松地进阶掌握K近邻算法。
K最近邻算法的基本原理是,对给定的训练数据集,对新的输入实例,在训练数据集中找到与该实例最近邻的K个实例,依据“少数服从多数”的原则,根据这K个实例中占多数的类,就把该实例分为这个类。
换言之,它实际上是利用训练数据集对特征空间进行划分,采用测量不同特征值之间的距离方法进行分类。如下图所示,给定了红色和蓝色的训练样本,绿色为测试样本。然后计算绿色点到其他点的距离,同时选取离绿点最近的k个点。如果选定k=1时,k个点全是蓝色,那预测结果就是绿色为类别1(蓝色);k=3时,k个点中两个红色一个蓝色,这里采取“少数服从多数”原则,那预测结果就是类别2(红色)。
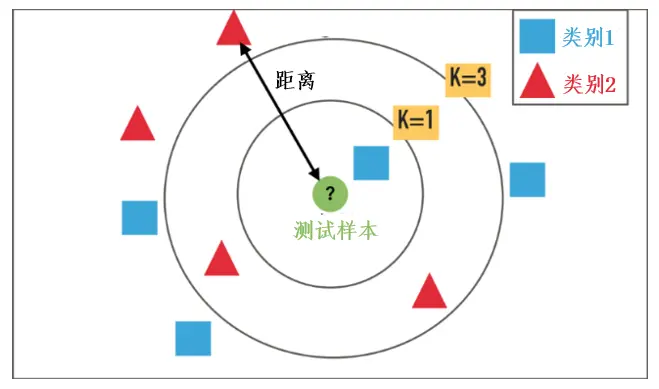
在K-NN算法中,K值的选择、实例之间距离的度量及分类决策规则是三个基本要素。
K值的选择会对分类结果产生重要影响。如果k值过小,新样本选择的范围就小。只有与新样本很近的点才会被选择到,那么模型就比较复杂,容易发生过拟合。如果k值过大,新样本选择的范围增大,那么模型就会变得简单,容易发生欠拟合。举个极端的例子,如果k的值是整个训练集的样本数,那么返回的永远是训练集中类别最多的那一类,也就失去了分类的意义。。
特征空间中两个实例点的距离是两个实例点相似程度的反映。K近邻的第一步,是找到x的最近邻。那么这个近邻怎么衡量呢?一般我们用距离来衡量,常见的有欧氏距离和曼哈顿距离。
欧式距离如下式
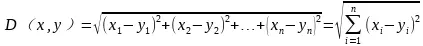
而曼哈顿距离如下式
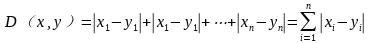
由输入实例的K个临近训练实例的多数决定输入实例的类别。这K个近临实例的权值可以相同,也可以根据一定的规则产生不同的权值,如离输入实例越近,权值相应也越大。此外,k近邻算法在实现时,要计算新样本与训练集中每一个实例的距离。这种线性搜索会大大增加时间的消耗,尤其是在数据量很大的情况下。为了提高效率,会使用KD树的方法。KD树是一种二叉树,主要是按训练集数据的不同维度的中位数来划分区域。
推荐使用Anaconda,它是一个用于科学计算的Python发行版。常见的科学计算类的库都包含在里面了,使得安装比常规python安装要容易。更适合新手用户实践上手。
下面实例分析我们将使anacoda内置的Scikit-learn(简称sklearn)来进行。sklearn是机器学习中常用的第三方模块,对常用的机器学习方法进行了封装,包括回归(Regression)、降维(DimensionalityReduction)、分类(Classfication)、聚类(Clustering)等方法。Sklearn具有简洁且易上手的特点.
首先使用下面代码在Anacoda内的spyder中生成数据集。注意语句%matplotlibinline是JupyterNotebook专用语句,用于在Notebook中直接显示图像。如果你是用其它的pythonIDE,如spyder或者pycharm,这个地方会报错,显示是invalidsyntax(无效语法)——直接注释掉这一句即可解决报错的问题。此外,KNN_Project_Data数据文件放置在路径D:/datanew/KNN_Project_Data下,读者可以根据自己的使用习惯放在自定义的路径下。
importpandas as pd
importnumpy as np
importmatplotlib.pyplot as plt
importseaborn as sns
#%matplotlibinline
df= pd.read_csv('D:/datanew/KNN_Project_Data')
df.head()
运行结果:
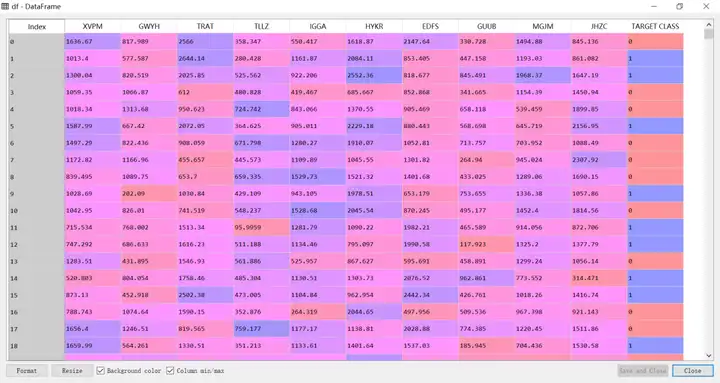
从上面运行程序得到的数据集标题头可以清楚看出,表中数据集包含10个变量(XVPM,GWYH, TRAT, TLLZ, IGGA, HYKR, EDFS, GUUB,MGJM,JHZC)和一个目标类(TARGETCLASS)。此目标类中包含给定参数的不同类。
正如我们已经看到的那样,数据集是不标准化的。如果我们不对数据集进行标准化操作,无法得到正确的分类结果。而Sklearn第三方模块提供了一种非常简单的方法来帮助用户来对数据进行标准化。使用下面代码进行数据集标准化操作,
fromsklearn.preprocessing import StandardScaler
scaler= StandardScaler()
scaler.fit(df.drop('TARGETCLASS', axis=1))
sc_transform= scaler.transform(df.drop('TARGET CLASS', axis=1))
sc_df= pd.DataFrame(sc_transform)
sc_df.head()
打开变量查看器窗口中的标准化的数据集变量sc_df,如下图所示
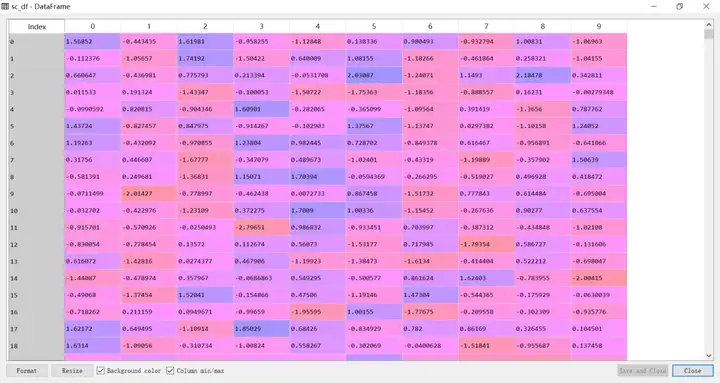
标准化后,通常我们将会对整个数据集进行划分。第一个数据集称为训练数据,另一个数据集称为测试数据。Sklearn第三方模块可以帮助用户简单地将数据集化分成几个部分。代码如下,
fromsklearn.model_selection import train_test_split
X= sc_transform
y= df['TARGET CLASS']
X_train,X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)
运行程序后,在变量窗口可以看到划分的数据集变量X_test,X_train, y_test, y_train
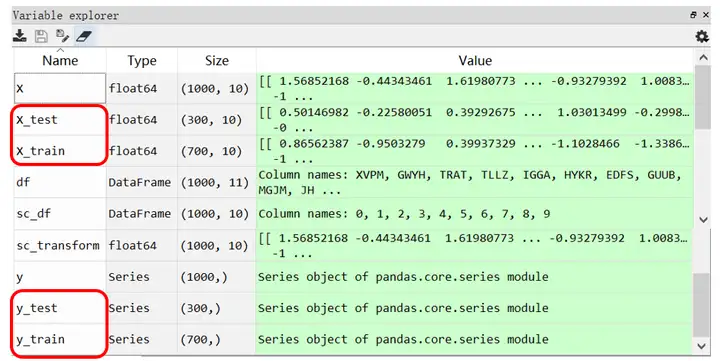
正如上文K最近邻算法基本原理部分中提到,K值的选择是一个非常重要的问题(也称调参)。我们希望能找到使用程序自动找出一个很好的K值,从而可以是模型的错误率最小化。具体实现程序代码如下:
fromsklearn.neighbors import KNeighborsClassifier
error_rates= []
fora in range(1, 40):
k = a
knn = KNeighborsClassifier(n_neighbors=k)
knn.fit(X_train, y_train)
preds = knn.predict(X_test)
error_rates.append(np.mean(y_test - preds))
plt.figure(figsize=(10,7))
plt.plot(range(1,40),error_rates,color='blue',linestyle='dashed', marker='o',
markerfacecolor='red', markersize=10)
plt.title('ErrorRate vs. K Value')
plt.xlabel('K')
plt.ylabel('ErrorRate')
运行后,会显示如下结果
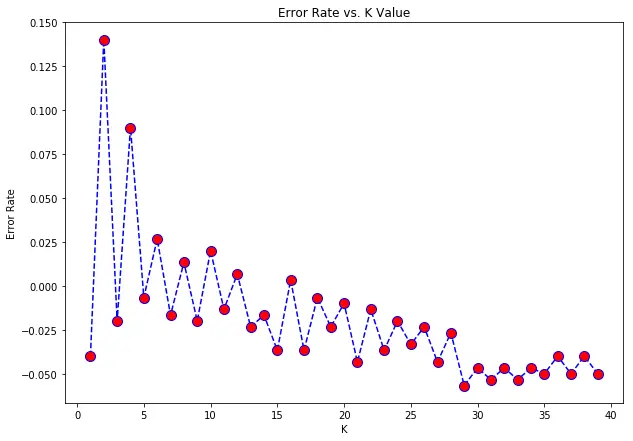
从图中可以看出,当K=30时,模型的错误率值开始趋于平稳,达到了一个非常理想的值。因此这里我们选取K=30,使用数据集X来实现K最近近邻算法,代码如下。
k= 30
knn= KNeighborsClassifier(n_neighbors=k)
knn.fit(X_train,y_train)
preds= knn.predict(X_test)
此后,需要对所建立的K-NN模型进行评估,代码如下,
fromsklearn.metrics import confusion_matrix, classification_report
print(confusion_matrix(y_test,preds))
print(classification_report(y_test,preds))
程序运行后,将显示classification_report,这是显示主要分类指标的文本报告,如下图所示。在报告中显示每个类别(0,1)的精确度(precision),召回率(recall),F1值等信息。其中,精确度是关注于所有被预测为正(负)的样本中究竟有多少是正(负)。而召回率是关注于所有真实为正(负)的样本有多少被准确预测出来了。
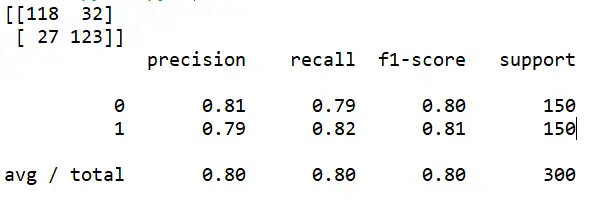
至此,我们使用了不到60行代码完成了数据集创建,划分,最优K值的寻找,K-NN算法模型建立以及评估一整套机器学习分类流程。避免了非常繁杂的数学公式以及算法理论。我们可以看出。K-NN算法非常其简单易用,整个算法中只用提供两个度量:k值和距离度量。同时也可以使用任意数量的类,而不仅仅是二进制分类器。这意味着向算法中添加新数据相当容易。



 手机端官网
手机端官网

 京公网安备 11010802020714号
京公网安备 11010802020714号