来源:北大青鸟总部 2023年04月25日 09:10
人工智能发展到今天,以深度学习和知识图谱为代表的感知智能(主要集中在对于图片、视频以及语音的能力的探究)和认知智能(涉及知识推理、因果分析等),得到越来越多的应用,知识图谱逐渐成为关键技术之一,现已被广泛运用到智能搜索、智能问答、个性化推荐、内容分发等领域。知识图谱在2012年由谷歌提出,旨在描述现实世界中存在的实体以及实体之间的关系。它把复杂的知识领域通过数据挖掘、信息处理、知识计量和图形绘制出来,探索知识领域的动态发展规律,它不是指某一特定的模型,是指一类模型、一种技术体系。

知识图谱作为近年在大数据时代下新颖的知识组织与检索技术,它的知识组织和展示的优势慢慢体现出来,越来越得到各行业的重视。知识图谱在很多场合上被用作让机器理解语言的背景知识库,它的根本意义就是能帮助机器理解语言。下面我们通俗易懂地介绍一下知识图谱中涉及的关键技术,以便于读者加深一些知识图谱的感性认识,为今后知识图谱的应用打下一定技术基础。
知识图谱通常以实体为节点形成一个大的网络,从实际业务需求出发,在知识实体之上抽象出数据模型,按实体自身、实体属性、实体关系,将多领域的信息关联起来,同时利用第三方数据,结合知识获取方法,填充图谱信息。
知识图谱的技术生命周期大致可分为六大步骤,按顺序依次为:知识建模、知识获取、知识加工、知识存储、知识校验、知识应用。
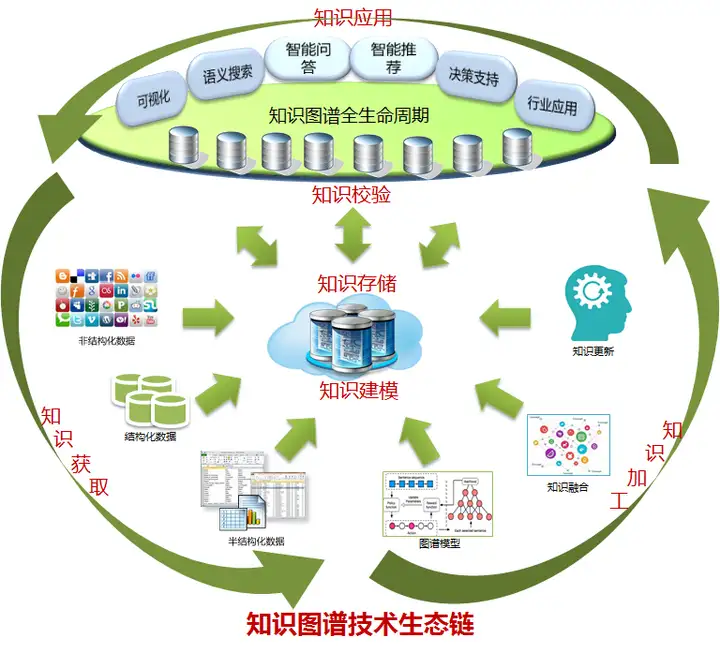
整个知识图谱技术生态链生命周期如上图,其流程是:
1、知识建模:对知识图谱进行构建,包括数据模型、知识模型等;
2、知识获取:接入采集和采购数据,进行数据标引,并根据指标计算得出未识别的实体基础数据;用实体对齐消歧服务进行实体识别,初步得到实体基础数据;
3、知识存储:将验证过的实体基础数据保存到知识库,训练机器学习模型,保存知识到知识图谱(特指图数据库)中;
4、知识加工:知识库将实体基础数据进行知识融合,进行知识计算服务;
5、知识校验:整个过程中进行验证和校验;
6、知识应用:基于以上技术支撑,实现知识图谱应用。
在武侠迷熟知的金庸武侠世界中,有一套号称“天下第一刚猛”的掌法——降龙十八掌,使用者配合浑厚的内力,无坚不摧、无固不破。虽招数有限,但每一招均具巨大的威力,是历代丐帮帮主的独门绝学。我们在这里可以把知识当作一类“龙”,借用一下金庸大侠描绘的降龙十八掌中颇具威力的六掌,来形容知识图谱的六大技术步骤如何“降龙”,方便读者理解。这六大招术对应知识图谱技术链分别是:
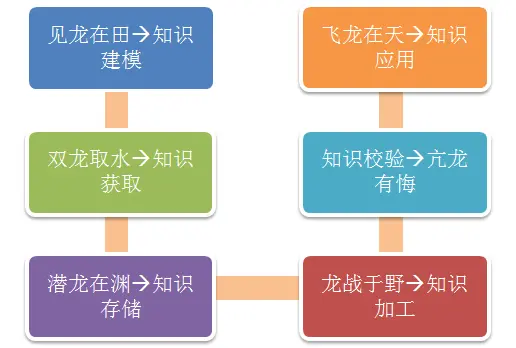
读者朋友疑惑了:“降龙”武功和人工智能技术有什么关系?别急,下面我们来逐一介绍。
降龙十八掌中的“见龙在田”这一招,是蓄势之后构建自身坚固防御的掌法,与构建知识图谱模型比较类似,是打基础的步骤。知识图谱的模型构建是整个技术链条重要的第一步,其质量直接决定了图谱应用的效果。知识图谱构建了实体与实体之间更深层次、更长范围的关联,增强了机器学习算法的挖掘能力,一定程度上提高了人工智能预测的准确性和多样性,也有效地弥补交互信息的稀疏或缺失。

通过图谱建模,其建立的Schema相当于数据模型,描述了领域下包含的类型(Type),与类型下描述实体的属性(Property),Property中实体与实体之间的关系为边(Relation),实体自带信息为属性(Attribute)。知识图谱建模的步骤如下:
(1) 确定实体(图谱中的节点),将实体抽取、合并,对不同来源的数据进行映射合并;
(2) 将实体属性与标签建模,利用属性来表示不同数据源中对实体的描述,对实体的全方位描述进行建模;
(3) 实体关系信息建模(图设计),记录描述各类抽象建模成实体的数据关系,支持分析关联;
(4) 多实体之间静态关联建模,实现围绕实体多种类数据的关联建模;
(5) 实体动态事件关联建模,将客观世界中实体动态发展与事件关联,利用时序记录实体的发展状况。
在知识采集的过程中,经常会遇到结构化和非结构化(包括半结构化)两种数据,我们可以把这两种数据比喻为两条“龙”。而在降龙十八掌中有一招就是“双龙取水”,这一招是双掌同时发出取敌要害,可以形象地比喻获取上述的结构化和非结构化知识数据。知识图谱的数据来源有类型多、来源广、数量大、模式繁杂等特点,相对传统的数据采集和抽取,难度是比较大的。
知识图谱可以将多源异构、多维的数据汇聚到一起,通过知识获取的技术手段,将不同来源、不同结构的数据进行知识提取,最后形成知识存入到知识图谱。针对不同种类的数据,需要利用不同的技术进行提取。
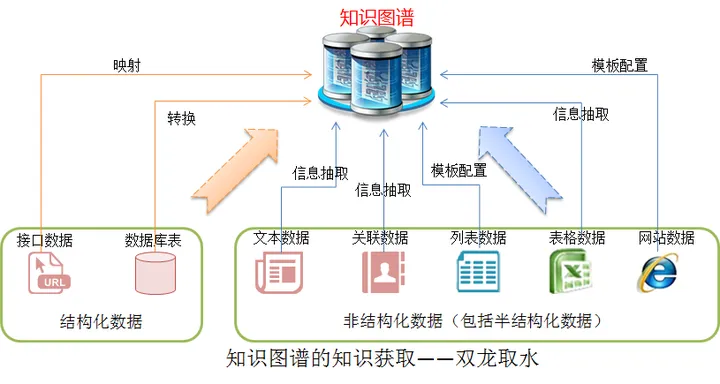
l 结构化数据的获取相对简单,做好数据的映射和转换,就可以进行常态化抽取。
l 对于半结构化数据,通常利用人机结合方式自动学习,针对不同结构的数据配置的数据源进行解析,主要识别文本或数据中的人名、地名、专业术语、时间等实体信息进行抽取。
l 对文本类的非结构化数据进行实体识别、关系抽取、概念抽取、事件抽取。通常面向特定领域的信息抽取可预先定义好抽取的关系类型,利用“启发式算法+人工规则”,实现自动抽取实体信息,同时使用机器学习算法训练系统来减少各种形式的噪音和不确定性,通过“有监督学习+先验知识”,为每一个决断进行复杂的可能性计算。在抽取过程中,通常会使用NLP分词、命名实体识别工具如NLPIR、LTP等工具进行监督学习和信息抽取。
潜龙在渊(又名:潜龙勿用)是降龙十八掌中积累了较大的内力然后蓄势而发的一招,相当于时刻准备着随时能够对敌人给予打击。知识图谱对知识存储也类似,是将知识和相关信息、数据进行存储,形成海量的知识库,以便后续进行知识图谱的应用。知识图谱的存储是基于图的数据结构,主要方式有:RDF(Resource Description Framework)存储和图数据库(Graph Database),知识图谱数据存储需要支持的基本数据存储有:三元组知识存储、事件信息存储、事态信息存储、使用知识图谱组织的数据存储。
当前项目上大部分使用neo4j进行知识图谱存储,neo4j的特点是采用原生图存储与处理,不支持AICD事物处理,不使用Schema。

在实际项目中,针对知识图谱的存储没有一种通用的能够解决所有问题的方案,主要还是依据数据特点进行数据存储结构的选择与设计,存储设计时需要考虑:基础存储可按数据场景选择使用关系型数据库、非关系型数据库或内存数据库;不在图数据库中统计分析计算,将需要进行统计分析计算的数据放到规划合适的存储中再进行统计分析;需要考虑快速推理与图计算等大数据存储的支持。
“龙战于野”的寓意为:在荒野与龙大战,是降龙十八掌中十分奥妙的招式,也是众多招式中覆盖范围大、纵横捭阖、恢弘大气的绝技。在知识图谱中为了获得结构化、网络化的知识体系,还需要进行知识加工,而知识加工的过程复杂,对数据进行各种复杂地整合、清洗、计算,用这一招“龙战于野”来比喻还是相对贴切的。
知识加工是一个知识数据处理过程的统称,包括知识融合、知识计算、知识更新等过程。通过数据的抽取,从原始数据里提取出实体关系和属性的知识要素,再经过知识融合,消除实体的支撑项和实体对象之间的奇异,得到一系列基本的事实描述,再经过知识计算(推理)、知识更新,最终形成知识图谱。

下面我们按这三个过程,简单介绍一下:
l 知识融合:将知识获取后得到的多源异构、信息多样、动态演化的知识通过冲突检测和一致性检测,对知识进行正确性判断、去粗取精。主要包括实体链接、知识合并两部分操作。
l 知识计算及推理:包括图挖掘计算、知识推理等。知识推理是指从已有的实体关系数据出发,进行计算推理,建立实体新关联,扩展和丰富知识网络,知识推理是构建知识图谱的重要手段和关键环节。典型的方法有:
属性值推理:比如根据树木的年轮可推断出其生长年份;
概念推理:如狼属于犬科,犬科属于食肉目,可以推出狼属于食肉目。
l 知识更新:知识图谱所获取的知识是不断动态新增的,知识更新基于不断流入的数据进行分析从而得到的类似事件实体的动态数据,新增数据后获得了新概念,需将新概念加入到知识库中。还有将新增或更新的实体、关系、属性、属性值加入知识库。典型的更新可以是:由大数据计算“热词”与已有实体比较,自动补充新实体;通过远程监督,当远程数据资源发生变化被监测到时,监督自身数据是否需要随之变化。
“亢龙有悔”的寓意是“盈不可久,步有虚实,可退可先”。在降龙掌法中,是一个圆转如意、可以随时修正的招术。知识图谱中,知识在积累、加工过程中,逐步会产生一些问题,需随时进行知识校验(也可以叫做知识的质量评估),不断修正“亢”(突出的情况),才能长期使用。知识校验是知识图谱构建的重要组成部分,通过校验对知识体系的可信度进行量化评估后,再进行知识纠偏来保证知识库的质量。
知识校验是贯穿整个知识图谱技术生态链的过程。在初期的模型设计过程中,需要严格规范模型及其类型、属性等等。如果不够规范,会导致错误传达到数据底层且不易纠错。在知识来源中获取的知识(数据)或多或少都包含着各种杂质,在模型层面上,添加人工校验方法与验证约束规则,保证导入数据的规范性进行知识校验。
对于实体间关系的准确性,如上下文关系是否正确、实例的类型是否正确,实例之间的关系是否准确等,可以利用实体的信息与图谱中的结构化信息计算一个关系的置信度,或看作关系对错与否的二分类问题。涉及到其他来源的数据,在数据融合的同时进行交叉验证,保留验证通过的知识。当图谱数据初步成型,在知识应用过程中,通过模型结果倒推出的错误,也有助于净化图谱中的杂质(如知识推理时出现的矛盾导致知识有误的情况)。
当知识库中的知识积累到一定程度,就是知识图谱显示威力的时候了,“飞龙在天”是降龙十八掌中威力巨大,具超强展现力的一招掌法。同样,知识应用也即知识图谱的“飞龙在天”,是最终开花结果的阶段。知识应用阶段能体现更规范的数据表示、更强的数据关联以及更深邃的数据价值。

当今知识图谱已经蓬勃发展,上图是网络上知识图谱的典型应用场景,可以看到知识图谱已经突破最早在智能搜索领域应用的初衷,快速发展到智能客服、推荐、情报分析、智能对话、辅助决策等等其他人工智能领域。
当前AI领域非常火热的语义搜索,就是基于知识图谱对用户输入进行理解,解决传统搜索中遇到的关键词语义多样性及语义消歧的难题,识别实体、概念和属性,并返回实体、关系、链接的数据等所产生的丰富结果。
语义搜索可以延伸发展到基于自然语言理解的智能问答系统。智能问答针对用户输入的自然语言进行解析,对用户查询意图进行分析与理解,从知识图谱中或目标数据中进行查询检索,生成候选答案并根据结果权重进行排序,给出用户问题的答案。
另外,可视化决策辅助也是知识图谱越来越多的应用方向之一,很多人工智能的实际应用中,通过图谱展示、统计分析、最短路径发现、多节点关联探寻等可视化技术手段,能够构建基于知识图谱的一体化决策辅助系统,以支撑用户进行知识决策辅助应用。
知识图谱可以建立为面向某一行业领域特定的知识图谱应用平台,比如目前知识图谱在风控领域上,更多应用于反欺诈、反洗钱、互联网授信、保险欺诈、银行欺诈、电商欺诈、项目审计作假、企业关系分析、罪犯追踪等场景中。
知识图谱是一个很庞大的技术体系,在人工智能领域中,可以说和深度学习是一样的繁杂和深奥,限于篇幅,本文仅仅是做一个科普,使读者朋友对知识图谱的技术链建立一个感性认识,并产生一定的兴趣,方便今后大家有机会时能更好地去研究和应用知识图谱体系。
知识图谱是知识工程的一个分支,以知识工程中语义网络作为理论基础,并且结合了机器学习、自然语言处理和知识表示和推理的最新成果,在解决大数据中文本分析和图像理解问题发挥重要作用。
知识图谱的发展目前还处于初级阶段,面临众多挑战和难题,如:知识库的构建有效策略和自动扩展、大规模的异构知识处理、推理规则学习、人机协作和人机边界问题、跨语言检索等等。

此外,知识图谱建立以后,对其运行后的管理、运维、人工监督等方面,也非常重要,应当尽量避免在知识图谱运维中因为新知识的错误发布对现有业务的影响,并将经过严格测试验证的知识图谱版本正式生效上线,最终保证知识图谱全生命周期各环节的数据质量。同时,通过知识图谱应用的使用记录及问题反馈带动知识图谱的运维优化,形成闭环全周期的多知识图谱间的运维管控。因此知识图谱的“数据生态”与“技术生态”,是需要不断地抽象总结再演绎细化的过程。
当前,知识图谱的地位越来越重要,可以说凡是有知识和关系的领域都可以用到知识图谱。事实上,知识图谱也已经成功俘获了大量客户,而且应用领域和客户数量还在不断增长中,感兴趣的读者朋友可以一直关注和持续学习。



 手机端官网
手机端官网

 京公网安备 11010802020714号
京公网安备 11010802020714号