来源:北大青鸟总部 2023年05月18日 13:38
今天我们要给大家补的知识点便是分布式消息系统Kafka。
在互联网海量数据、高并发、高可用、低延迟的要求下,使用消息系统来进行数据的转发、系统之间的解藕是必不可少的,学习Kafka就先来看看Kafka的典型使用场景。
场景1之消息系统,即将生产者应用和消费者应用解藕,生产者的消息通过Kafka发送,消费者订阅Kafka的消息。
场景2之日志收集,即通过Kafka收集各种服务的日志,再以统一接口服务的方式开放给各个consumer。
场景3之用户活动跟踪,即通过Kafka记录web用户或app用户的活动,消费者订阅该数据进行实时的分析。
场景4之运营指标,即通过Kafka记录运营指标、监控数据,消费者再订阅这些数据进行报警。
场景5之流式处理,即对接sparkstreaming、storm来实时处理数据。
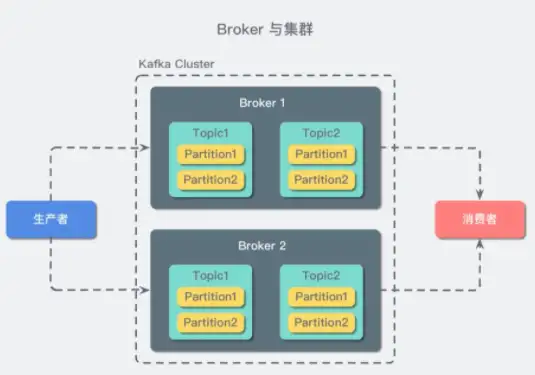
接着我们再继续介绍Kafka的基本名词概念,在Kafka中有Broker、Topic、Partition、Segment、Producer、Consumer五个基本概念。所谓Broker就是Kafka节点,一个服务器实例,存储消息队列数据;所谓Topic就是消息,比如购买商品后会有商品购买成功的推送,这就是一类信息;所谓partition就是分组,一个topic可以分为多个partition,比如购买商品后可按用户地域进行消息的推送,北京地域是一个partition,上海地域是一个partition;所谓segment就是分段,将partition分为多段,存储消息;所谓producer就是生产者,负责生产消息;所谓consumer就是消费者,负责消费消息。Kafka工作的流程就是producer发布消息,系统为每类数据创建一个topic,在broker集群持久化和备份具体的Kafka消息,consumer订阅topic进行消费消息。
作为一个开源软件,Kafka最重要的能力便是提供API。在Kafka中有四大API:即生产者API、消费者API、流API、连接器API。
通过生产者API,消息的生产者便可以直接与集群中的Kafka服务器连接,发送流数据到一个或多个Kafka的topic中。
通过消费者API,消息的消费者便可以直接与集群中的Kafka服务器连接,消费Kafka中topic的流消息。
通过流API,可顺利的从topic中消费输入流,生产输出流,在流处理中,通过Kafkastreams api也将数据提供到大数据平台、Cassandra、spark中进行数据分析。
通过连接器ConnectorAPI,开发者可以构建、运行可重复使用的生产者与消费者。
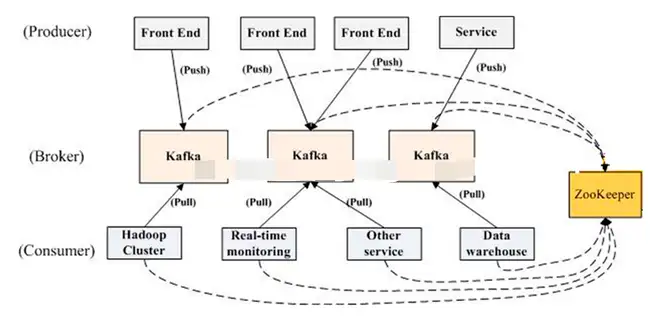
作为一个分布式消息系统,Kafka是如何实现分布式的呢?Kafka需要与zookeeper一起使用才能对外提供分布式消息系统能力。我们假设有这样的一个场景,在Kafka集群中,有一个很大的topic要处理。我们先把这个topic放在代理服务器Broker1、broker2、broker3上,在broker1/2/3上分别包含分区partition1/2/3。当一个broker启动时,首先会向zookeeper注册自己的broker、topic、partition信息等meta元信息。当消费者启动时,也会向zookeeper节点注册自己的信息,监听生产者的变化。那么数据是如何分布各个节点呢?事实上每个节点的数据都会在整个集群进行复制,比如在broker1中每个分区中的数据都会复制一份到该集群中的Broker2、broker3,由broker1作为主节点对生产者和消费者提供数据,当broker1节点挂掉时,通过使用zookeeper工具在剩下的broker2、broker3中选举出新的主节点对外提供服务。因此在Kafka集群中所有的数据在每个broker节点都有,无论何时都保障了服务的高可用。
最后我们看看在Kafka中如何保障数据的可靠性呢?
第一是消息顺序读写,如果生产者producer先写入了消息1,再写入消息2,那么消费者consumer则会先消费1再消费2;
第二是消息写入到所有的Kafka节点后才会被认为该消息已提交;
第三是一旦消息已提交,只要有一个Kafka节点存活,数据就不会丢失;
第四就是消费者consumer只能读取已提交的消息。通过这些机制,足以保障Kafka系统数据的可靠性了。
在本文,我们介绍了从使用场景、基本概念、重要能力、分布式保障、可靠性保障五个方面介绍了Kafka,如果在面试中面试官有问到Kafka或消息队列相关的知识点,再也不怕被问住了~



 手机端官网
手机端官网

 京公网安备 11010802020714号
京公网安备 11010802020714号