来源:北大青鸟总部 2023年08月15日 08:53
大数据时代对数据的处理分析提出了很多需求,企业用户希望能从业务数据生成报表、进行运营分析、进行实时推荐计算。因此,在大数据处理分析领域出现了很多工具,列式数据库Clickhouse、Hbase提供了存储和分析能力,Hadoop家族中的MapReduce、HDFS提供了离线计算能力,Hive以数据仓库的形态提供了简单易学的分析能力,实时计算引擎Flink更是提供了流批处理计算能力,可谓是各有千秋啊!不过工具千千万,唯有适合自己的才是最好的,今天我们要介绍的便是Presto
Presto是Facebook公司开源的分布式SQL查询引擎,支持PB级别的数据计算,之所以在众多分析引擎中选择它,主要是因为它是一个能够独立运行、不依赖其他外部系统;此外简单的数据结构使得大部分数据的接入很容易;最后丰富的插件接口可以对接很多数据源系统。基于内存计算的模式、基于流水线设计边运行边出结果的运行模式也使得Presto很快就能获取处理数据。综上原因,诸如阿里、美团等互联网巨头在数据分析中也使用Presto做底层引擎。
Presto的架构如下所示,它包含Client、DiscoveryService、Coordinator、Worker、Connector五大部分。Client包含presto自带的客户端、通过API调用的JDBC客户端;DiscoveryService是一个注册中心,所有的Worker节点都向其进行注册,Coordinator从其获取worker节点,有点类似微服务架构中的“生产者-注册中心-消费者”之间的关系;Worker负责从Connector获取数据,执行数据分析任务;Connector负责获取数据源信息,可以接收来自文件系统如HDFS的数据,也可以接收数据库如Mysql、Clickhouse的数据,甚至是消息队列如Kafka中的数据。
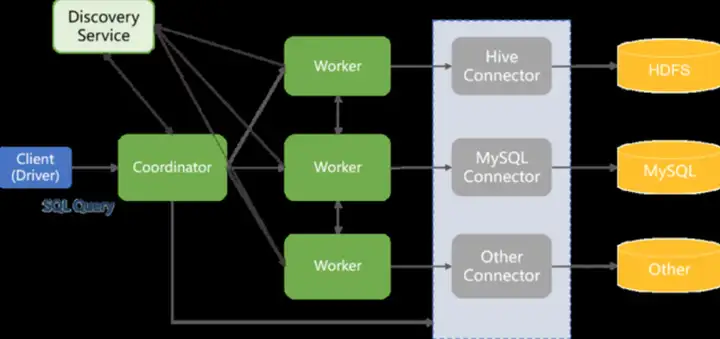
那么在Presto中如何执行一个SQL查询任务呢?简单来说,大概是这样的:用户在客户端发出一个SQL查询请求,Coordinator接受来自客户端的请求,并对该SQL语句进行解析,生成查询计划,按查询计划依次生成SQLQueryExecution—》SQLStageExecution—〉HTTPRemotePlan,把最后的Plan任务分配给到Worker节点;Worker节点根据任务内容从Connector中获取数据,执行计算,计算完毕后把结果给到Coordinator,Coordinator获取结果把结果写入缓存,客户端不断轮询Coordinator中的查询结果,一次任务执行完毕,把数据给用户展示出来。
介绍完Presto如何执行一个SQL任务后,我们再来看看它的数据结构和存储模型。在Presto中的数据结构是三层模型,Catalog-》Schema-〉Table,Catalog对应一个数据源,Schema对应数据源中的数据库,Table对应数据库中的表。在Presto的存储模型中包含Page-》Block,Page是多行数据的集合(每一行又包含多个列的数据),也是Presto计算处理的最小数据单元,Block是具体的一列数据。清晰了Presto的数据结构和存储模型,在接入Presto时就比较清晰了。
Presto处理速度快,除了Worker节点基于内存进行运算处理之外,在Worker节点内部、Worker节点之间都是采用流水线模型进行计算。这给用户造成的感觉就是很快,刚输入就有结果了,先看前面的结果再看后面的结果。
同样是数据处理分析引擎,处理速度的差别却是各不相同,这主要和使用工具的架构及运行原理有关系。早期Facebook是使用Hive做数据分析处理,后来因为实在太慢了,所以才自己开发写了Presto,据说同样的一个SQL查询任务,在Hive中需要差不多一分钟,但Presto人中却不到1秒,那今天我们也感受一波Facebook公司的数据分析处理历史吧。
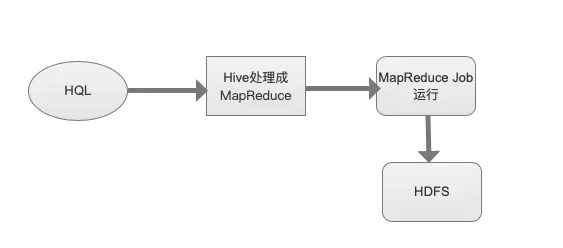
关于Hive,它是基于Hadoop的数据仓库工具,使用Hive也可以进行数据查询分析处理,我们一起来看看Hive中又是如何运转的呢?在Hive中,所有的HQL语句转化成数据查询任务,所有的数据在进行处理前会划分成大小相同的数据,经过Map模型初次处理数据,得到中间结果,再经过Reduce模型二次处理中间结果数据,最后得到分析数据,存储在HDFS。在该模型中,所有的数据分析处理需要经过多次转换成中间结果,比较慢;其次在MR模型中所生成的中间数据都是存储在磁盘中的,每次数据进入磁盘,再从磁盘读取出来,非常的耗费IO,时间延迟太长了。
介绍完Presto后,我们再回归现实,了解下互联网现况。互联网、移动互联网、物联网、5G、人工智能、云计算等技术的不断发展,越来越多数据的产生,企业精细化运营的要求,在催生了大量的数据处理分析工具之时,也催生了诸如数据仓库、数据集市、数据湖、数据中台等业态,不断的在给大数据领域输送力量,对于数据分析人才的诉求也一直有增无减,后浪们,我们一起加油吧!



 手机端官网
手机端官网

 京公网安备 11010802020714号
京公网安备 11010802020714号